The ScyllaDB team is pleased to announce the release of ScyllaDB Enterprise 2021.1.0, a production-ready ScyllaDB Enterprise major release. After more than 2500 commits originating from five open source releases, we’re excited to now move forward with ScyllaDB Enterprise 2021. This release marks a significant milestone for us. While we’ve said for years we are a drop-in replacement for Apache Cassandra we are now also a drop-in replacement for Amazon DynamoDB.
The ScyllaDB Enterprise 2021.1 release is based on ScyllaDB Open Source 4.3, promoting open source features to Enterprise level support, including our DynamoDB-compatible API (Alternator) and Lightweight Transactions (LWT).
ScyllaDB Image (for AWS EC2, GCP) is now based on Ubuntu 20. More below.
Related Links
- Read more about ScyllaDB Enterprise here.
- Get ScyllaDB 2021.1 (customers only, or 30-day evaluation)
- Upgrade from 2020.1.x to 2021.1.y
- Upgrade from ScyllaDB Open Source 4.3 to ScyllaDB 2021.1
ScyllaDB Enterprise customers are encouraged to upgrade to ScyllaDB Enterprise 2021.1, and are welcome to contact our Support Team with questions.
Deployment
- ScyllaDB Enterprise packages are newly available for:
- .tar file format: our Unified Installer is now available (see below)
- Ubuntu 20
- GCP: ScyllaDB now has an official GCP Image (see below)
- The setup utility now uses chrony instead of ntp for timekeeping on all Linux distributions. This makes setup more regular. #7922. Expedition to this is using systemd-timesyncd when it’s installed by default #8339
- Dynamic setting of
aio-max-nrbased on the number of CPUs, mostly needed for large machines like EC2 i3en.24xlarge #8133 - Change Data Capture (CDC) is not part of ScyllaDB Enterprise 2021.1. CDC will be added to a follow up 2020.1.x release with a ScyllaDB Open Source 4.4 compatible API.
- Head warning: new base OS for ScyllaDB Image: Ubuntu 20
To date, ScyllaDB Enterprise images for EC2 (AMI) were based on CentOS 7. - Beginning with this release, the AMI and GCP image will be based on Ubuntu 20.
Existing CentOS AMI will continue to be supported, including upgrades to the 2021.1.x version, but it is highly recommended to move clusters to the new AMI (not just upgrade), as new AMI will only be provided with Ubuntu. Running a ScyllaDB cluster with two types of OS is supported but might be hard to manage. The new AMI will support the scyllaadm user for login.
ScyllaDB Enterprise 2020.1 AMI for EC2 and Image for GCP will be published soon.
New Features in 2021.1
Space Amplification Goal (SAG) for ICS
First introduced in 2020.1.6, and now part of 2021.1, ICS SAG allows a new option to set a Space Amplification Goal (SAG) in Incremental Compaction Strategy (ICS). SAG is a new property that allows users to control space amplification. It’s intended for users with overwrite-intensive workloads, as this new feature consists of triggering compaction to deduplicate data whenever the compaction strategy finds the space amplification has crossed the configured goal. Please note that the SAG value is not an upper bound on space amplification, but the compaction strategy will be continuously working to control the space amplification according to the configured value.
The name of this new property is space_amplification_goal. Choose a value between 1 and 2, where a value closer to 1 leads to more write amplification and smaller space amplification, and value closer to 2 leads to less write amplification and higher space amplification. The penalty on write amplification is reduced as much as possible by being more aggressive on the two largest size tiers, but still allowing accumulation of data on the smaller tiers.
Let’s see how it works in action: If SAG was set with a value of 1.5, compaction would be triggered when the second-largest tier reaches half the size of the largest tier. That’s because the largest tier is assumed to contain the entire data set, therefore the second-largest tier contributes with a space amplification of 0.5, making the estimated space amplification go beyond the threshold value. By compacting those two tiers together in a process called cross-tier compaction, the actual space amplification will be reduced to below the space amplification goal.
space_amplification_goal is disabled (null) by default. For full ICS compaction options reference, see here.
ScyllaDB Unified Installer
ScyllaDB is now available as an all-in-one binary tar file. You can download the tar file from the download page.
Unified Installer should be used when one does not have root privileges on the server.
For installation on an air-gap server, with no external access, it is recommended to download the standard packages, copy them to the air gap server and install using the standard package manager. More here. #6626 #6949
Remove the Seed Concept in Gossip
The concept of seed and the different behavior between seed nodes and non-seed nodes generate a lot of confusion, complication, and error for users. Beginning with this release, seed nodes are ignored in the Gossip protocol. They are still in use (for now) as part of the init process. More on seedless nodes here. #6845
Alternator, Our DynamoDB-Compatible API
The following additions been made to Alternator since 2020.1:
- New: Alternator’s SSL options (Alternator Client to Node Encryption on Transit)
Until this release, Alternator SSL configuration was set in the sectionserver_encryption_optionsof the ScyllaDB configuration file. The name was misleading, as the section was also used for the unrelated node-to-node encryption on transit.
Beginning with this release, a new section alternator_encryption_options is used to define Alternator SSL.
The old section is supported for backward compatibility, but it is highly recommended to create the new section in scylla.yaml with the relevant parameters, for example:
alternator_encryption_options:
certificate: conf/scylla.crt
keyfile: conf/scylla.key
priority_string: use default- Docker: add an option to start Alternator with HTTPS. When using ScyllaDB Docker, you can now use
--alternator-https-portin addition to the existing--alternator-port. #6583 - Implement FilterExpression
AddingFilterExpression– a newer syntax for filtering results of Query and Scan requests #5038Example usage in query API:aws dynamodb query \ --table-name Thread \ --key-condition-expression "ForumName = :fn and Subject = :sub" \ --filter-expression "#v >= :num" \ --expression-attribute-names '{"#v": "Views"}' \ --expression-attribute-values file://values.jsonSource: https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Query.html
- Additional filtering operators #5028
- All operators are now supported. Previously, only the “
EQ” operator was implemented. - Either “
OR” or “AND” of conditions (previously only “AND”). - Correctly returning
CountandScannedCountfor post-filter and pre-filter item counts, respectively.
- All operators are now supported. Previously, only the “
- Mandatory configurable write isolation mode #6452
Alternator allows users to choose the isolation level per table. In ScyllaDB Enterprise 2021.1, a user needs to explicitly set the default value in scylla.yaml:forbid_rmw– Forbids write requests which require a read before a write. Will return an error on read-modify-write operations, e.g., conditional updates (UpdateItem with a ConditionExpression).only_rmw_uses_lwt– This mode isolates only updates that require read-modify-write. Use this setting only if you do not mix read-modify-write and write-only updates to the same item, concurrently.always– Isolate every write operation, even those that do not need a read before the write. This is the slowest choice, guaranteed to work correctly for every workload. This was the default in 2020.1For example, the following configuration will set the default isolation mode to always, which was the default in ScyllaDB 2020.1alternator_write_isolation: alwaysNote: Alternator will not run without choosing a default value!
- Allow access to system tables from Alternator REST API.
If aQueryorScanrequest intercepts a table name with the following pattern:.scylla.alternator.KEYSPACE_NAME.TABLE_NAME, it will read
the data from ScyllaDB’sKEYSPACE_NAME.TABLE_NAMEtable.Example: in order to query the contents of ScyllaDB’ssystem.large_rows, passTableName='.scylla.alternator.system.large_rows'to aQuery/Scanrequest.
#6122 - Add support for ScanIndexForward
Alternator now support theScanIndexForwardoption of a query expression. By default, query sort order is ascending. SettingScanIndexForwardtoFalseparameter reverses the order. See AWS DynamoDB Query API #5153
Security related updates
- gnutls vulnerability: GNUTLS-SA-2020-09-04 #7212
- New optional CQL ports (19042, 19142, see Shard aware CQL ports below)
- Allow users to disable CQL unencrypted native transport by setting it to zero #6997
CQL Extensions
- A new CQL protocol extension allows client drivers to distinguish between lightweight transactions (LWT) and non-LWT statements. The intent is to prefer the primary replica when sending LWT statements, to reduce transaction aborts due to contention. More information
- Shard aware CQL ports: new CQL port (19042 by default) is being opened for the so-called “advanced shard-aware drivers”. It works exactly as the typical 9042 works for existing drivers (connector libraries), but it allows the client to choose the specific shard to connect to by precise binding of the client-side (ephemeral) port. Also, a TLS alternative is supported, under port 19142.
Read this article and the documentation for more information
Additional Features
- Support for SSTable “md” format (CASSANDRA-14861) #4442
- Docker: a new
--io-setup Ncommand line option, which users can pass to specify whether they want to run thescylla_io_setupscript or not. This is useful if users want to specify I/O settings themselves in environments such as Kubernetes, where runningiotuneis problematic. #6587 - Requests Role or User are now tracked in the tracing output #6737
- Tracing improvements: better messages for single-key queries, and activities in the cache. The commits come with some examples.
- REST API: Add long polling to
StorageServiceRepairAsyncByKeyspaceGet#6445 - Docker: ScyllaDB on Docker now supports the passing of extra arguments to ScyllaDB #7458
- SSTable Reshard and Reshape in upload to directory
Reshard and Reshape are two transformation on SSTables:- Reshard – Splits an SSTable that is owned by more than one shard (core) into multiple SSTables that are each owned by a single shard. For example, when restoring data from a different server, importing SSTables from Apache Cassandra, or changing the number of cores in a machine (upscale)
- Reshape – Rewrite a set of SSTable to satisfy a compaction strategy’s criteria. For example, restoring data from an old backup, before the strategy update.
Before this release, ScyllaDB first moved files from upload to a data directory, and then reshaped and reshard the data. In some cases, this resulted in an unacceptably high number of files in the data directory.
Beginning with ScyllaDB Open Source 4.2 and ScyllaDB Enterprise 2021.1, ScyllaDB first reshards and reshapes the SSTables in the upload directory, and only then moves them to the data directory. This ensures SSTables already match the number of cores and proper compaction strategy when moved to the data directory, resulting in a smaller number of overall compactions.
SSTable Reshard and Reshape also happens on boot (if needed) prior to making the node online – making sure the node doesn’t have a lot of backlog work to do in addition to serving traffic.
- Setup: swapfile setup is now part of scylla_setup.
ScyllaDB setup already warns users when the swap is not set. Now it prompts for the swap file directory #6539
Setup: default root disk size is increased from 10G to 30GB. scylla-machine-image #48 - CQL: support Filtering on counter columns #5635
- Compaction: Allow Major compactions for TWCS. Make major compaction aware of time buckets for TWCS. That means that calling a major compaction with TWCS will not bundle all SSTables together, but rather split them based on their timestamps. #1431
- Restore: ScyllaDB no longer accepts online loading of SSTable files in the main directory. New tables are only accepted in the upload directory.
- ScyllaDB-tools-java are now based on Apache Cassandra 3.11 tools and use Java 11.
Tools
- node_exporter is an agent used to report OS level metrics to ScyllaDB Monitoring Stack. In this release installed node_exporter is updated from 0.17.0 to 1.0.1
- Nodetool getendpoints can return wrongs nodes list #7134
- The JMX management interface was enabled for Java 11 for Debian systems. It was already supported, but a packaging error resulted in installation problems.
- nodetool now support the
gettraceprobabilitycommand #7265
Performance Optimizations
Enable binary search in SSTable promoted index
The “promoted index” is a clustering key index within a given partition stored as part of the SSTable index file structure. The primary purpose is to improve the efficiency of column range lookup in large, with many rows, partitions.
Before ScyllaDB Enterprise 2021, lookups in the promoted index are done by linearly scanning the index (the lookup is O(N)). However, for large partitions, this approach is costly and inefficient. It consumes a lot of CPU and I/O and does not deliver efficient performance.
Starting from this release, the reader performs a binary search on the MC SSTable promoted index (the search time is now O(log N)).
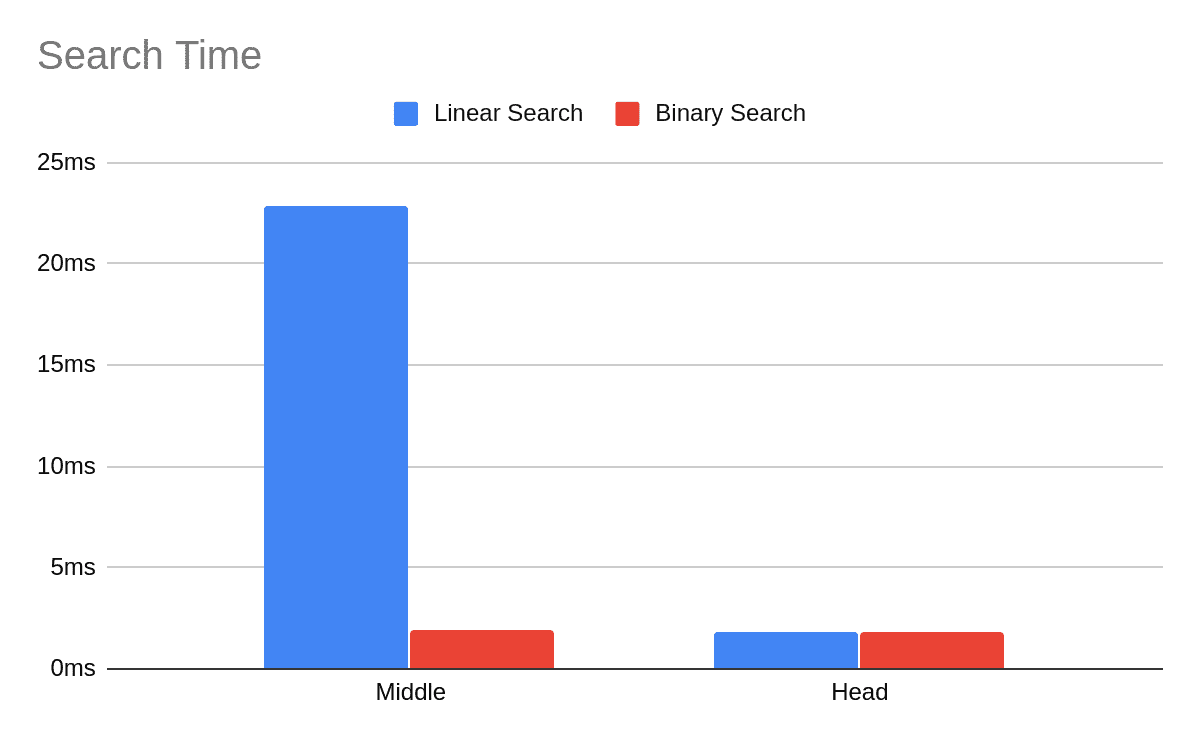
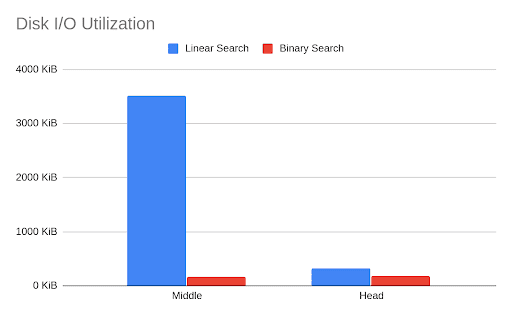
For example, testing performed with large partitions consisted of 10,000,000 rows (a value size of 2000, partition size of 20 GB and an index size of 7 MB) demonstrates that the new release is 12x faster, CPU utilization is 10x times smaller, disk I/O utilization is 20x less.
The following charts present the differences in search time and disk utilization for two cases:
- Middle: Queried row is in the middle of a (large) partition
- Head: Queried row is at the head, as the first element of a (large) partition
As expected, the binary search shines in the middle case and has similar results in the (unlikely) case of searching for the first element.
More details on the results here #4007
Additional Performance Improvements
(Citing ScyllaDB Open Source issue numbers, where applicable)
- Cleanup: nodetool cleanup procedure is used after adding nodes, to remove data that was migrated to the new nodes. The calculation that determines which sstables needed to be rewritten (cleaned up) was inefficient and could cause stalls in queries running at the same time, so it was optimized #6662
- JSON: More of the code base was migrated from the jsoncpp library to the rjson library, improving JSON performance, JSON is heavily used in ScyllaDB Alternator.
- Materialized Views (MVs): After a repair, bootstrap, or decommission (or a similar operation), the node receiving new data must update materialized views. This is done by reading staging sstables containing the new data, row by row, and updating the view rows corresponding to those rows. There can be large numbers of such sstables (one per vnode per peer), and reading from such large numbers of sstables requires a lot of memory. This memory usage is now dramatically reduced by exploiting the property that per-vnode sstables have few overlaps, and reusing the partitioned_sstable_set (which we use for leveled compaction strategy, which has similar properties) to avoid reading from all those SSTables at once. #6707
- Repair: moving from to
btree_setforrepair_hasheliminate the need for large allocation which cause stalls #6190 - The ScyllaDB cache and memtable implementations now use a btree instead of a red-black tree. This improves performance in cache-intensive and write-intensive workloads. More here
- UTF8 validation of large cells causes latency spikes. In this release, UTF8 validation is updated to work on fragmented buffers to fix this. #7448
- Over-aligned SSTable reads due to file buffer tracking #6290
- Performance: using the wrong scheduling group for different operations #8591 #8508
- Performance: Large SSTables with many small partitions often require large bloom filters. The allocation for the bloom filters has been changed to allocate the memory in steps, reducing the chance of a reactor stall. #6974
- Performance: SSTables being compacted by Cleanup, Scrub, Upgrade can potentially be compacted by regular compaction in parallel #8155
- Performance: Few of the Local system tables from `
system` namespace, likelarge_partitionsdo not use gc grace period to 0, which may result in millions of tombstones being needlessly kept for these tables, which can cause read timeouts. Local system tables use LocalStrategy replication, so they do not need to be concerned about gc grace period. #6325 - Performance: removing a potential stall on SSTable clean up #6662 #6730
- Performance: bypass cache when generating view updates from streaming #6233
- Performance: Streaming during bootstrapping is slow due to compactions #5109
Configuration
The following new configuration parameters are available in this release:
max_concurrent_requests_per_shard: Maximum number of concurrent requests a single shard can handle before it starts shedding extra load. By default, no requests will be shed. Default: max (disabled)native_shard_aware_transport_port_ssl: Like native_transport_port_ssl, but clients are forwarded to specific shards, based on the client-side port numbers. Default: 19142.enable_sstables_md_format: Enable SSTables ‘md’ format to be used as the default file format (requires enable_sstables_mc_format). Default: truemax_memory_for_unlimited_querywas replaced by two new parameters;max_memory_for_unlimited_query_soft_limit: Maximum amount of memory a query, whose memory consumption is not naturally limited, is allowed to consume, e.g. non-paged and reverse queries. This is the soft limit, there will be a warning logged for queries violating this limit. Default:1 MBmax_memory_for_unlimited_query_hard_limit: Replace the oldmax_memory_for_unlimited_query. Maximum amount of memory a query, whose memory consumption is not naturally limited, is allowed to consume, e.g. non-paged and reverse queries. This is the hard limit, queries violating this limit will be aborted. Default:100 MB
schema_registry_grace_period: Time period in seconds after which unused schema versions will be evicted from the local schema registry cache. Default: 1 second
LWT
- SERIAL reads and lightweight transactions which had no impact on the database (didn’t apply) are now fully linearizable. #6299
(See Apache Cassandra open issue: CASSANDRA-12126)
Monitoring
ScyllaDB Enterprise 2021.1.0 Dashboard are available with ScyllaDB Monitoring Stack 3.7 or later
- For new metrics compare to ScyllaDB Enterprise 2020.1 see here
- For new metrics compare to ScyllaDB Open Source 4.3 see here
Stability and Bug Fixes (from 2020.1.0)
- CQL: Numbers of the ‘
decimal’ type that had negative scale (which translates to positive exponent:1.2e1has negative scale, while1.2e-1has positive scale), when casted to a floating-point type (‘CAST x AS float‘), thew the node into a long loop, effectively making it unavailable. #6720 - CQL: A bug where impossible range restrictions (
WHERE a > 0 AND a < 0) was processed incorrectly #5799 - Stability: Internal schema change CQL queries should not be used for distributed tables #6700
- CQL:
min()/max()return wrong results on some collections #6768 - Stability: a rare memory leak caused by improper commitlog usage from hints manager #6776 #6409
- Stability: Row-level repair was made more robust against hash collisions. Row-level repair uses a hash to identify mismatched rows. A weak hash is used to reduce computation and network costs, but this results in the possibility of collisions. Now, when a collision is detected, repair will copy the colliding rows (even if there was no problem) rather than fail the repair.
- Stability: Repair now uses a uuid to identify repair jobs #6786
- Stability: compaction should print a unique id to correlate start and finish log messages #6840
- Alternator: tracing was fix for
GetItemandBatchItem#6891 - Stability: TWCS compaction: partition estimate can become 0, causing an assert in sstables::prepare_summary() #6913
- scyllatop: using `
metricPattern` fails with “dictionary changed size during iteration” #7488 - Stability: Cleanup compaction in KA/LA SSTables may crash the node in some cases #7553
- Stability: secondary index updates failing after upgrade to 4.2.0 due to missing
system_schema.computed_columns. The problem is limited to secondary indexes created before ScyllaDB 3.2, which had their `idx_token` column incorrectly not marked as computed #7515 - Stability: schema integrity issues that can arise in races involving materialized views may cause segmentation fault and coredump happened during starting after scylla was killed #7420
- Stability: provide strong exception guarantees from
load_sstable()#6658 - Stability: Incrementally delete resharded sstables as they’re retired #7463
- Stability: Node may get stuck in schema disagreement loop when bootstrapping sequentially #7396
- CQL:
token_restriction: invalid_request_exceptiononSELECTs with both normal and token restrictions #7441 - LWT:
store column_mapping’s for each table schema version upon a DDL change - Code refactoring: Move
write()methods from classsstableto classsstable_writer#3012 - Stability: Clean cluster issued ‘
Exceptional future ignored‘ right after being started with no load on it #7352 - UX: Make batchlog size warning clearer #7367
- Stability: ASCII validation of large cells causes large allocations #7393
- Stability: ScyllaDB 4.1.7 crashing on repairs (uncaught exceptions) #7285
- Stability: Shutting down database hangs in dtest-debug #7331
- Stability: Useless linearization on large data during validation, of either type
bytesorstring-derived, potentially cause stalls due to reclaiming #7318 - Stability:
NEW_NODEshould be sent after listening for CQL clients has started #7301 - Stability (counters): runtime error: signed integer overflow cannot be represented in type ‘
long int‘ #7330 - Non root install (Logging): can’t find scylla log by
journalctl --user -xe#7131 - Non root install: nonroot install: ubuntu18 failed to start for `
NOFILE rlimit too low` #7133 - CQL (found with Jepsen): Aborted reads of writes which fail with “
Not enough replicas available” #7258 - Stability: Unsynchronized cross-shard memory operations caused by incorrectly used
updateable_value#7310 - Stability: Reduce unnecessary
VIEW_BACKLOGupdates in gossip #5970 - Non root install:
systemctl –user enable scylla-server.service failedon Ubuntu 18 #7288 - Non root install: Got offline mode warnings on nonroot mode #7286
- CQL: (
LOCAL_/EACH_)QUORUMconsistency calculation is broken when RF=0 #6905 - Install:
scylla_prepare:get_set_nic_and_disks_config_valueis not defined #7276 - Stability: RPC server still has handlers registered in dtests involving repair-based operations #7262
- Stability: Query pager can try to get keys from empty vector of
result::partitions#7263 - Install:
scylla_cpuscaling_setup: Got warning when installingscylla-cpupower.service#7230 - Stability:
disable_autocompaction_nodetool_test failed: std::runtime_error (Too early: storage service not initialized yet)#7199 - Stability:
abstract_replication_strategy::do_get_rangesis passed a reference totoken_metadatathat may be invalidated if it yields #7044 - Install: scylla_setup doesn’t support to skip install of hugepages or libhugetlbfs-bin package #7182
- Stability: init – Startup failed:
std::runtime_error(Could not find tokens for 10.0.0.155 to replace) during large-partition-4d test #7166 - Init: scylla4 process fails to restart (perftune.py: error:
argument --mode: invalid choice: 'None') #6847 - CQL: Forbid adding new fields to UDTs used in partition key columns #6941
- Stability: Make
allocation_sectiondecay the reserves over time #325 (from 2015!) - Init: scylla_setup failing with dependency errors #7153
- CQL (found with Jepsen): Weird return values from batch updates #7113
- Non root install: scylla-python3 isn’t loaded for setup scripts #7130
- Stability: some non-prepared statements can leak memory (with set/map/tuple/udt literals) #7019
- Stability: Reactor stall for 6 ms in
sstables::seal_summary()#7108 - Stability: coredump while node hit enospc:
Assertion '!this->_future && this->_state && !this->_task' failed#7085 - Stability: gossip: Apply state for local node in shadow round #7073
- Stability: Hinted handoff is using very long timeout to sending some hints #7051
- Build: dist: scylla-python3 should be separated repository #6751
- Stability: Track
repair_metacreated on both repair follower and master #7009 - Stability: Failed compaction : compaction_manager – compaction failed:
sstables::malformed_sstable_exception (consumer not at partition boundary)#6529 - Stability: sstable code needs to close files in error paths #6448
- Stability: ScyllaDB setup failed:
unit mdmonitor.service is not found or invalid#7000 - UX: scylla_setup: include swap size in the prompt #6947
- Untyped result sets may cause segfaults when parsing disengaged optionals #6915
- UX: scylla_setup: default “
done” when there is no disk to choose from #6760 - Stability: Startup failed:
std::runtime_error ({shard 0: fmt::v6::format_error (invalid type specifier), shard 1: fmt::v6::format_error (invalid type specifier)})'])due to an adjusted in format strings in log messages after changing string format library #6874 - Setup: scylla_setup does not abort RAID setup when no free disk available #6860
- CQL: Filtering captures uninitialized/deleted values of certain types #6295
Stability: repair: Relax node selection in bootstrap when nodes are less than RF #6744 - UX: scylla_prepare: Improve error message on missing CPU features #6528
- CQL:
NULLcounters treated as 0 #6382 - CQL:
IN(NULL)yields different results with prepared statements #6369 - CQL:
LIKEfilter ignored on column key #6371 - CQL:
NULLand empty text are considered equal #6372 - Stability: scylla_coredump_setup always fails on CentOS 7 #6789
- Setup:
node_exporter_install --forcefailing #6782 - repair: inaccurate log from
check_failed_ranges#6785 - repair: log recoverable errors as warnings rather than info messages #5612
- scylla setup fails on Oracle Linux Artifact: OS variant not recognized #6761
- scylla_util.py: duplication on detecting distribution #6691
- scylla_setup: on RAID prompt, strange output when passing comma separated multiple disks #6724
- Stability: connection storm when attempting to achieve shard-per-connection #5239
- Stability: Nodetool Repair failing on keyspace with
std::runtime_error (row_diff.size() != set_diff.size())#6252 - ScyllaDB_setup: scylla_setup failed to setup RAID when called without
--raiddevargument #7627 - ScyllaDB_setup: scylla_raid_setup: use sysfs to detect existing RAID volume, which may not be able to detect existing RAID volume by device file existence. #7383
- Stability: rare race condition in
compaction_writerdestructor may cause Segmentation fault during scylla stop, for example with CDC traffic #7821 - CQL: Impossible
WHEREcondition returns a non-empty slice #5799 - Stability: reactor stalled during repair abort #6190
- Stability: a rare race condition between topology change (like adding a node) and MV insert may cause a
seastar::broken_promise (broken promise)error message, although there is no real error #5459 - UX:
scylla-housekeeping, a service which checks for the latest ScyllaDB version, return a “cannot serialize” error instead of propagating the actual error #6690 - UX: scylla_setup: on RAID disk prompt, typing the same disk twice cause traceback #6711
- Stability: Counter write read-before-write is issued with no timeout, which may lead to unbounded internal concurrency if the enclosing write operation timed out. #5069
- replace_first_boot_test and replace_stopped_node_test fail in 4.1: Replace failed to stream #6728
- Setup: scylla_swap_setup: swap size become 0 when memory size less than 1GB #6659
- Stability: ScyllaDB freezes when casting a decimal with a negative scale to a float #6720
- Log: Compaction data reduction log message misses % sign #6727
- Stability: Prevent possible deadlocks when repair from two or more nodes in parallel #6272
- Setup: Sscylla fails to identify recognize swap #6650
- Setup: scylla_setup: systemctl shows up warning after scylla_setup finished #6674
- Storage: SSTable upgrade has a 2x disk space requirement #6682
- Stability: Compaction Backlog can be calculated incorrectly #6021
- UX: CQL transport report a broken pipe error to the log when a client closes its side of a connection abruptly #5661
- Nodetool: for a multi DC cluster using a non-network topology strategy, Nodetool decommission can not find a new node in local dc despite the node exist #6564
- Monitoring: Use higher resolution histograms gets more accurate values #5815 #4746
- ScyllaDB will now ignore a keyspace that is removed while being repaired, or without tables, rather than failing the repair operation. #5942 #6022
- Monitoring new compaction_manager backlog metrics
REST APIstorage_service/ownership/ (get_effective_ownership)can cause stalls #6380 - Wrong order of initialization in messaging service constructor #6628
- Stream ended with unclosed partition and coredump #6478
- Stability: Classify queries based on initiator, instead of target table #5919
- Setup: scylla_raid_setup cause traceback on CentOS7 #6954
- CQL: Impossible to set list element to null using
scylla_timeuuid_index#6828 - Setup: Using Systemd slices on CentOS7, with percentage-based parameters does not work and generate warnings and error messages during instance (ami) load #6783
- Stability: Commitlog replay segfaults when mutations use old schema and memtable space is full #6953
- Setup: scylla_setup on Ubuntu 16 / GCE fails #6636
- Stability: a race condition when a node fails while it is both streaming data (as part as repair) and is decommissioned. #6868 #6853
- Stability: index reader fails to handle failure properly, which may lead to unexpected exit #6924
- Stability: a rare deadlock when creating staging SSTable, for example when repairing a table which has materialized views #6892 #6603
- Stability: Fix issues introduced by classifying queries based on initiator, instead of target table (#5919), introduced in 4.2 #6907 #6908 #6613
- Stability: TWCS compaction: partition estimate can become 0, causing an assert in
sstables::prepare_summary()#6913 - Stability: Post-repair view updates keep too many SSTable readers open #6707
- Stability: Staging SSTables are incorrectly removed or added to backlog after
ALTER TABLE/TRUNCATE#6798 - Stability: Fix schema integrity issues that can arise in races involving materialized views #7420 #7480
- Install: python scripts core dump with non-default locale #7408
- Stability: Possible read resources leak #7256
- Stability: materialized view builder: ScyllaDB stucks on stopping #7077
- LWT: Aborted reads of writes which fail with “
Not enough replicas available” #7258 - Stability: “
No query parameter set for a session requesting a slow_query_log record” error while tracing slow batch queries #5843 - Stability:
appending_hash<row>ignores cells after first null #4567 - Stability: Race in schema version recalculation leading to stale schema version in gossip, and warning that schema versions differ on nodes after scylla was restarted with require resharding #7291
- Stability: Unnecessary LCS Reshape compaction after startup due to overly sensitive SSTable overlap ratio #6938
- AWS: update enhanced networking supported instance list #6991
- Stability: large reactor stalls when recalculating TLS Diffie-Helman parameters #6191
- Stability: a bug introduced in 4.2 may cause unexpected exit for expire timers #7117
- Stability: too aggressive TWCS compactions after upgrading #6928
- redis:
EXISTScommand with multiple keys causesSEGV#6469 - Stability: Status of drained node after restart stayed as DN in the output of “nodetool status” on another node #7032
- Alternator: ignore disabled SSESpecification #7031
- Alternator: return an error for create-table, but the table is created #6809
- Stability: RPC handlers are not unregistered on stop #6904
- Stability: Schema change, adding a counter column into a non-counter table, is incorrectly persisted and results in a crash #7065
- Debugging: trace decoding on doesn’t work #6982
- Debugging: gdb scylla databases gives the same address for different shards #7016
- Stability: Connection dropped: RPC frame LZ4 decompression failure #6925
- Stability: repair may cause stalls under different failure cases #6940 #6975 #6976 #7115
- Stability: Materialized view updates use incorrect schema to interpret writes after base table schema is altered #7061
- Stability: Possible priority inversion between hints and normal write in
storage_proxy#7177 - Stability: Segfault in evaluating multi-column restrictions #7198
- Stability: in some rare cases, a node may crash when calculating effective ownership #7209
- Alternator: a bug in the
PutItemimplementation withwrite_isolation = always_use_lwt. In case of contention but a successful write, the written data could have not matched the intent. #7218 - Stability: in some rare cases, error recovery from an out-of-memory condition while processing an unpaged query that consumes all of available memory may cause the coordinator node to exit #7240
- Stability: Coredump during the decommission process on decommissioning node #7257
- Stability: out-of-range range tombstones emitted on reader recreation cause fragment stream monotonicity violations #7208
- Stability: race in schema version recalculation leading to stale schema version in gossip #7200
- Security: upgrade bundled gnutls library to version 3.6.14, to fix gnutls vulnerability CVE-2020-13777 #6627
- Stability: an integer overflow in the index reader, introduced in 3.1.0. The bug could be triggered on index files larger than 4GB (corresponding to very large SSTables) and result in queries not seeing data in the file (data was not lost). #6040
- Stability: a rare race condition between a node failure and streaming may cause abort #6414, #6394, #6296
- Stability: When hinted handoff enabled, commitlog positions are not removed from
rps_setfor discarded hints #6433 #6422. This issue would occur if there are hint files stored on disk that contain a large number of hints that are no longer valid – either older thangc_grace_secondsof their destination table, or their destination table no longer exists. When ScyllaDB attempts to send hints from such a file, invalid hints will cause memory usage to increase, which may result in “Oversized allocation” warnings to appear in logs. This increase is temporary (ends when hint file processing completes), and shouldn’t be larger than the hint file itself times a small constant. - Stability: potential use after free in storage service when using API call
/storage_service/describe_ring/#6465 - Stability: Issuing a reverse query with multiple
INrestrictions on the clustering key might result in incorrect results or a crash. For example:
CREATE TABLE test (pk int, ck int, v int, PRIMARY KEY (pk, ck));
SELECT * FROM test WHERE pk = ? AND ck IN (?, ?, ?) ORDERED BY ck DESC;
#6171 - Row cache is incorrectly invalidated in incremental compaction (used in ICS and LCS) #5956 #6275
- Stability (CQL): Using prepare statements with collections of tuples can cause an exit #4209
- LWT: In some rare cases, a failure may cause two reads with no write in between that return different value which breaks linearizability #6299
- Alternator: Alternator
batch_put_itemitem with nesting greater then 16 yieldClientError#6366 - Alternator: alternator: improve error message in case of
forbid_rmwforbidden write #6421 - Setup: scylla does save coredumps on the same partition that ScyllaDB is using #6300
- Stability: online loading of SSTable files in the main directory is disabled.
Till now, one cloud upload tables either in a dedicated upload directory, or in the main data directory.
The second, also used by Apache Cassandra, proved to be dangerous, and is disabled from this release forward. - Stability:
multishard_writercan deadlock when producer fails, for example when, during a repair, a node fail #6241 - Stability: fix segfault when taking a snapshot without keyspace specified
nodetool status returns wrong IPv6 addresses #5808 - Docker: docker-entrypoint.py doesn’t gracefully shutdown ScyllaDB when the container is stopped #6150
- CQL: Allow any type to be casted to itself #5102
- CQL:
ALTERing compaction settings for table also setsdefault_time_to_liveto 0 #5048 - Stability: Crash from
storage_proxy::query_partition_key_range_concurrentduring shutdown #6093 - Stability: When speculative read is configured a write may fail even though enough replicas are alive #6123
- Cloud Formation: Missing i3.metal in Launch a ScyllaDB Cluster using Cloud Formation. scylla-machine-image #31
- scylla-tools-java: cassandra-stress fails to retry user profile insert and query operations scylla-tools-java #86
- scylla-tools-java: sstableloader null clustering column gives
InvalidQueryExceptionscylla-tools-java #88 - scylla-tools-java: sstableloader fails with uppercase KS trying to load into lowercase when importing few years old cassandra scylla-tools-java #126
- scylla-tools-java: nodetool: permission issues when running nodetool scylla-tools-java #147
- scylla-tools-java: via cqlsh not possible to escape special characters such as ‘ when used as FILTER for UPDATE scylla-tools-java #150
- Alternator:
KeyConditionswith “bytes” value doesn’t work #6495 - Alternator: wait for schema agreement after table creation #6361
- Repair based node operations is disabled by default (same as 4.0)
- Coredump setup: clean coredump files #6159
- Coredump setup: enable coredump directory mount #6566
- Stability: scylla init is stuck for more than a minute due to mlocking all memory at once #6460
- Upgrade: when required, for example, during upgrade, to use an old SSTable format, ScyllaDB will now default to LA format instead of KA format. New clusters will always use MC format. #6071
- Stability: Reject replacing a node that has left the ring #8419
- Tools: nodetool cfstats cause a deadlock in nodetool #7991
- Tools: sstableloader doesn’t work with Alternator tables if “
-nx” option is used #8230 - Debug: messaging service: be more verbose when shutting down servers and clients #8560
- Thrift: The ability to write to non-thrift tables (tables which were created by CQL
CREATE TABLE) from thrift has been removed, since it wasn’t supported correctly. Use CQL to write to CQL tables. #7568 - Stability:
reader_concurrency_semaphore: readmission leaks resources #8493 - Stability: materialized views: nodes may pull old schemas from other nodes #8554
- Install: node_exporter does not install on Debian #8527
- Install:scylla_raid_setup returns ‘
mdX is already using‘ even it’s unused #8219 - Install: scylla_coredump_setup: don’t run
apt-getwhensystemd-coredumpis already installed #8185 - Install: ScyllaDB doesn’t use
/etc/security/limits.d/scylla.conf#7925 - Stability: reader_concurrency_semaphore: inactive reads can block shutdown #8561
- Install: scylla_raid_setup: Ubuntu does not able to enable
mdmonitor.service#8494 - ScyllaDB AMI: Ubuntu AMI: ScyllaDB server isn’t up after reboot #8482
- Install: dist: increase
fs.aio-max-nrvalue for other apps #8228 - Stability: a ScyllaDB crash at a specific timing when using encryption at rest may leave a file in unreadable state.
- Stability: unbounded memory usage when consuming a large run of partition tombstones
- Stability: Compaction Backlog controller will misbehave for time series use cases #6054
- UX: unnecessary warning warnings for small batches #8416
- Stability: a possible race condition in MV/SI schema creation and load may cause inconsistency between base table and view table #7709
- Install: bad permissions on node_exporter installed from ScyllaDB #6222
- CQL: unpaged query is terminated silently if it reaches global limit first. The bug was introduced in ScyllaDB 4.3 #8162
- Stability: missing dead row marker for KA/LA file format #8324. Note that the KA/LA SSTable formats are legacy formats that are not used in latest ScyllaDB versions.
- Stability: a regression on cleanup compaction’s space requirement introduced in ScyllaDB 4.1, due to unlimited parallelism #8247
- Stability: ScyllaDB crash when the IN marker is bound to null #8265
- Stability: Repairing a table with TWCS potentially cause high number of parallel compaction #8124
- Stability: Failing to start ScyllaDB after reboot of machine
Startup failed: seastar::rpc::timeout_error (rpc call timed out)#8187
20 May 2021