ScyllaDB takes full advantage of all available memory to provide blazing-fast query response times with consistently low latencies.
How ScyllaDB Maximizes the Usage of Memory
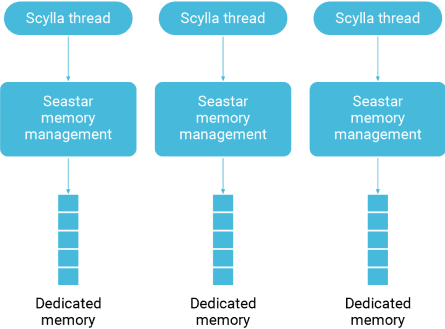
During startup, ScyllaDB inspects the node’s hardware and tries to claim all available memory for itself (apart from that reserved to the operating system), as memory is the most critical resource for any NoSQL database. The allocated memory is divided and assigned to each of the single threaded shards running in the node, each pinned to a different CPU core. This approach allows ScyllaDB to efficiently allocate memory to each CPU’s core in a shared-nothing NUMA-friendly manner and avoid any typical blocking operations or memory locks, and is referred to as lock-free memory management.
NOTE: In a shared environment this can severely impact performance or execution of other running applications. In such deployments users can configure a limit to the amount of memory ScyllaDB consumes.
Memtable and Row-Based Cache
One major section of memory allocated within ScyllaDB is for the memtable, an in-memory structure used on the write path to queue incoming writes and updates before they are flushed to a persistent SSTable on disk. Note, the same data is immediately written to the commitlog for durability.
The second section is for a row-based cache. Normally, in Linux based operating systems, data is fetched in 4KB blocks from storage. However, in practice, many database reads are fetching far less data. This results in read amplifications and inefficiency of the Linux cache. By contrast, ScyllaDB completely bypasses the Linux cache during reads and leverages its own highly efficient row-based cache.
Memory allocation in ScyllaDB is dynamic and as-needed. There are no static blocks or reserved set-asides. For example, in a read-only workload, cache will consume all of the memory. If writes start, memory will be reclaimed from cache and used for creation of memtables.