The ScyllaDB team is pleased to announce the release of ScyllaDB Open Source 4.2, a production-ready release of our open source NoSQL database.
ScyllaDB is an open source, NoSQL database with superior performance and consistently low latencies. Find the ScyllaDB Open Source 4.2 repository for your Linux distribution here. ScyllaDB 4.2 Docker is also available.
ScyllaDB 4.2 includes performance and stability improvements, more operations to the Alternator API (our Amazon DynamoDB-compatible interface) and bug fixes. The release also improves query performance by adding a binary search to SSTable promoted indexes (see below).
Please note that only the last two minor releases of the ScyllaDB Open Source project are supported. Starting today, only ScyllaDB Open Source 4.2 and ScyllaDB 4.1 are supported, and ScyllaDB 4.0 is retired.
Related Links
New features in ScyllaDB 4.2
Performance: Enable binary search in SSTable promoted index
The “promoted index” is a clustering key index within a given partition stored as part of the SSTable index file structure. The primary purpose is to improve the efficiency of column range lookup in large, with many rows, partitions.
Before ScyllaDB 4.2, lookups in the promoted index are done by linearly scanning the index (the lookup is O(N)). However, for large partitions, this approach is costly and inefficient. It consumes a lot of CPU and I/O and does not deliver efficient performance.
Starting from this release, the reader performs a binary search on the MC SSTable promoted index (the search time is now O(log N)).
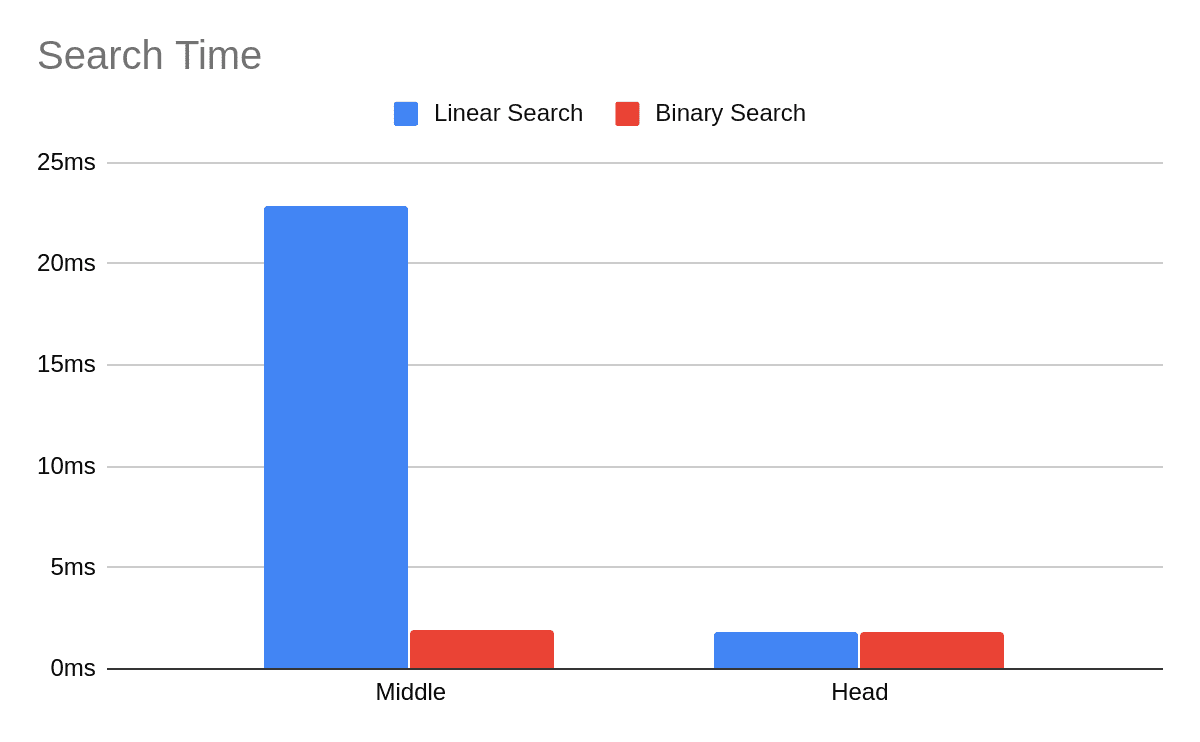
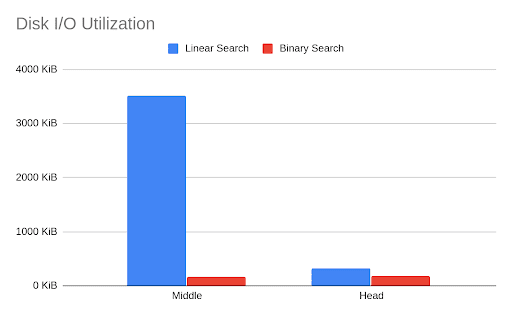
For example, testing performed with large partitions consisted of 10,000,000 rows(a value size of 2000, partition size of 20 GB and an index size of 7 MB) demonstrates that the new release is 12x faster, CPU utilization is 10x times smaller, disk I/O utilization is 20x less.
The following charts present the differences in search time and disk utilization for two cases:
- Middle: Queried row is in the middle of a (large) partition
- Head: Queried row is at the head, as the first element of a (large) partition
As expected, the binary search shines in the middle case and has similar results in the (unlikely) case of searching for the first element.
More details on the results here #4007
Alternator
- New Alternator’s SSL options (Alternator Client to Node Encryption on Transit)
Till this release, Alternator SSL configuration was set in the sectionserver_encryption_optionsof ScyllaDB configuration file. The name was misleading, as the section was also used for the unrelated node-to-node encryption on transit.
Starting from this release, a new section alternator_encryption_options is used to define Alternator SSL.
The old section is supported for backward compatibility, but it is highly recommended to create the new section in scylla.yaml with the relevant parameters, for example
alternator_encryption_options:
certificate: conf/scylla.crt
keyfile: conf/scylla.key
priority_string: use default
- docker: add an option to start Alternator with HTTPS. When using ScyllaDB Docker, you can now use
--alternator-https-portin addition to the existing--alternator-port. #6583 - Implement FilterExpression
Adding FilterExpression – a newer syntax for filtering results of Query and Scan requests #5038Example usage in query API:
aws dynamodb query \
--table-name Thread \
--key-condition-expression "ForumName = :fn and Subject = :sub" \
--filter-expression "#v >= :num" \
--expression-attribute-names '{"#v": "Views"}' \
--expression-attribute-values file://values.json
Source: https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Query.html - Alternator: support additional filtering operators #5028
- All operators are now supported. Previously, only the “EQ” operator was implemented.
- Either “OR” or “AND” of conditions (previously only “AND”).
- Correctly returning Count and ScannedCount for post-filter and pre-filter item counts, respectively.
Additional Features
- SSTable Reshard and Reshape in upload to directory
Reshard and Reshape are two transformation on SSTables:- Reshard – Splitting a SSTable, that is owned by more than one shard (core), into SSTables that are owned by a single shard, for example, when restoring data from a different server, importing sstSSTables from Apache Cassandra, or changing the number of cores in a machine (upscale)
- Reshape – Rewrite a set of SSTable to to satisfy a compaction strategy’s criteria., for example, restoring data from an old backup, before the strategy update.
Until this release, ScyllaDB first moved files from upload to to data directory, and then reshaped and reshard the data. In some cases, this results in a too high number of files in the data directory.
Starting from ScyllaDB 4.2, ScyllaDB first reshard and reshape the SSTables in the upload dir, and only then move them to data directory. This ensures SSTables already match the number of cores and compaction strategy when moved to the data directory, resulting in a smaller number of overall compactions.
SSTtable Reshard and Reshape also happens on boot (if needed) prior to making the node online – making sure the node doesn’t have a lot of backlog work to do in addition to serving traffic.
More on this in commits
https://github.com/scylladb/scylla/commit/94634d9945064d7be41b21ac2af0ae36cef37873
https://github.com/scylladb/scylla/commit/7351db7cab7bbf907172940d0bbf8b90afde90ba
- Setup: swapfile setup is now part of
scylla_setup.
ScyllaDB setup already warns users when the swap is not set. Now it prompts for the swap file directory #6539 - Setup: default root disk size is increased from 10G to 30GB. scylla-machine-image #48
Experimental features in ScyllaDB 4.2
- Change Data Capture (CDC). While functionally complete, we are still testing CDC to validate it is production-ready towards GA in a following ScyllaDB 4.x release. No API updates are expected. Refer to the ScyllaDB Open Source 4.1 Release Notes for more information.
Monitoring:
For Metics updates from 4.1 to 4.2, see here.
ScyllaDB 4.2 dashboard isare available in the latest ScyllaDB Monitoring Stack release 3.2.4 or later.
Other bugs fix and updates in the release
- CQL: Impossible WHERE condition returns a non-empty slice #5799
- Stability: reactor stalled during repair abort #6190
- Stability: a rare race condition between topology change (like adding a node) and MV insert may cause an “seastar::broken_promise (broken promise)” error message, although there is no real error #5459
- UX: scylla-housekeeping, a service which checks for the latest ScyllaDB version, return a “cannot serialize” error instead of propagating the actual error #6690
- UX: scylla_setup: on RAID disk prompt, typing the same disk twice cause traceback #6711
Stability: Counter write read-before-write is issued with no timeout, which may lead to unbounded internal concurrency if the enclosing write operation timed out. #5069
replace_first_boot_test and replace_stopped_node_test fail in 4.1: Replace failed to stream #6728 - Setup: scylla_swap_setup: swap size become 0 when memory size less than 1GB #6659
- Stability: ScyllaDB freezes when casting a decimal with a negative scale to a float #6720
- Log: Compaction data reduction log message misses % sign #6727
- Stability: Prevent possible deadlocks when repair from two or more nodes in parallel #6272
- Setup: Sscylla fails to identify recognize swap #6650
- Setup: scylla_setup: systemctl shows up warning after scylla_setup finished #6674
CDC: cdc: report unexpected exceptions using “error” level in generation management code #6557 - Storage: SSTable upgrade has a 2x disk space requirement #6682
Stability: Compaction Backlog can be calculated incorrectly #6021 - UX: cql transport report a broken pipe error to the log when a client closes its side of a connection abruptly #5661
- Nodetool: for a multi DC cluster using a non- network topology strategy, Nodetool decommission can not find a new node in local dc despite the node exist #6564
- Monitoring: Use higher resolution histograms gets more accurate values #5815 #4746
- ScyllaDB will now ignore a keyspace that is removed while being repaired, or without tables, rather than failing the repair operation. #5942 #6022
- Monitoring new compaction_manager backlog metrics
- REST API storage_service/ownership/ (get_effective_ownership) can cause stalls #6380
- Performance: over-aligned SSTable reads due to file buffer tracking #6290
- Wrong order of initialization in messaging service constructor #6628
- Stream ended with unclosed partition and coredump #6478
- CDC: failed to restore cdc log table from snapshot for postimage enabled only with refresh operation #6561
- CDC: wrong value for set in cdc_log table after second insert #6084
- CDC: reactor stalled up to 17000 ms after change cdc log table property #6098
- Stability: Classify queries based on initiator, instead of target table #5919
- Setup: scylla_raid_setup cause traceback on CentOS7 #6954
- CQL: min()/max() return wrong results on some collections and User Defined Type, naively comparing just the byte representations of arguments. #6768
- CQL: Impossible to set list element to null using scylla_timeuuid_index #6828
- Setup: Using Systemd slices on CentOS7, with percentage-based parameters does not work and generate warnings and error messages during instance (ami) load #6783
- Stability: Commitlog replay segfaults when mutations use old schema and memtable space is full #6953
- Setup: scylla_setup on Ubuntu 16 / GCE fails #6636
- Stability: a race condition when a node fails while it is both streaming data (as part as repair) and is decommissioned. #6868 #6853
- Stability: index reader fails to handle failure properly, which may lead to unexpected exit #6924
- Stability: a rare deadlock when creating staging sstable, for example when repairing a table which has materialized views #6892 #6603
- Stability: Fix issues introduced by classifying queries based on initiator, instead of target table (#5919), introduced in 4.2 #6907 #6908 #6613
- Stability: TWCS compaction: partition estimate can become 0, causing an assert in sstables::prepare_summary() #6913
- Stability: Post-repair view updates keep too many SSTable readers open #6707
- Stability: Staging SSTables are incorrectly removed or added to backlog after ALTER TABLE / TRUNCATE #6798
- Stability: Fix schema integrity issues that can arise in races involving materialized views #7420 #7480
- Install: python scripts core dump with non-default locale #7408
- Stability: Possible read resources leak #7256
- Stability: materialized view builder: ScyllaDB stucks on stopping #7077
- LWT: Aborted reads of writes which fail with “Not enough replicas available” #7258
- Stability: “No query parameter set for a session requesting a slow_query_log record” error while tracing slow batch queries #5843
- Stability: appending_hash<row> ignores cells after first null #4567
- Stability: Race in schema version recalculation leading to stale schema version in gossip, and warning that schema versions differ on nodes after scylla was restarted with require resharding #7291
- CQL: min()/max() return wrong results on some collections and User Defined Type, naively comparing just the byte representations of arguments. #6768
- CQL: Impossible to set list element to null using scylla_timeuuid_index #6828
- Stability: Unnecessary LCS Reshape compaction after startup due to overly sensitive SSTable overlap ratio #6938
- AWS: update enhanced networking supported instance list #6991
- Stability: large reactor stalls when recalculating TLS diffie-helman parameters #6191
- Stability: a bug introduced in 4.2 may cause unexpected exit for expire timers #7117
- Stability: too aggressive TWCS compactions after upgrading #6928
- redis: EXISTS command with multiple keys causes SEGV #6469
- Performance: removing a potential stall on sstable clean up #6662 #6730
- Stability: Status of drained node after restart stayed as DN in the output of “nodetool status” on another node #7032
- Alternator: ignore disabled SSESpecification #7031
- Alternator: return an error for create-table, but the table is created #6809
- Stability: RPC handlers are not unregistered on stop #6904
- Stability: Schema change, adding a counter column into a non-counter table, is incorrectly persisted and results in a crash #7065
- Debugging: trace decoding on doesn’t work #6982
- Debugging: gdb scylla databases gives the same address for different shards #7016
- CDC: better classify errors when fetching CDC generations #6804
- Stability: Connection dropped: RPC frame LZ4 decompression failure #6925
- Stability: repair may cause stalls under different failure cases #6940 #6975 #6976 #7115
- Stability: Materialized view updates use incorrect schema to interpret writes after base table schema is altered #7061
- Stability: Possible priority inversion between hints and normal write in storage_proxy #7177
- Stability: Segfault in evaluating multi-column restrictions #7198
- Stability: in some rare cases, a node may crash when calculating effective ownership #7209
- Alternator: a bug in the PutItem implementation with write_islation = always_use_lwt. In case of contention but a successful write, the written data could have not matched the intent. #7218
- Stability: in some rare cases, error recovery from an out-of-memory condition while processing an unpaged query that consumes all of available memory may cause the coordinator node to exit #7240
- Stability: Coredump during the decommission process on decommissioning node #7257
- Stability: out-of-range range tombstones emitted on reader recreation cause fragment stream monotonicity violations #7208
- Stability: race in schema version recalculation leading to stale schema version in gossip #7200
28 Oct 2020