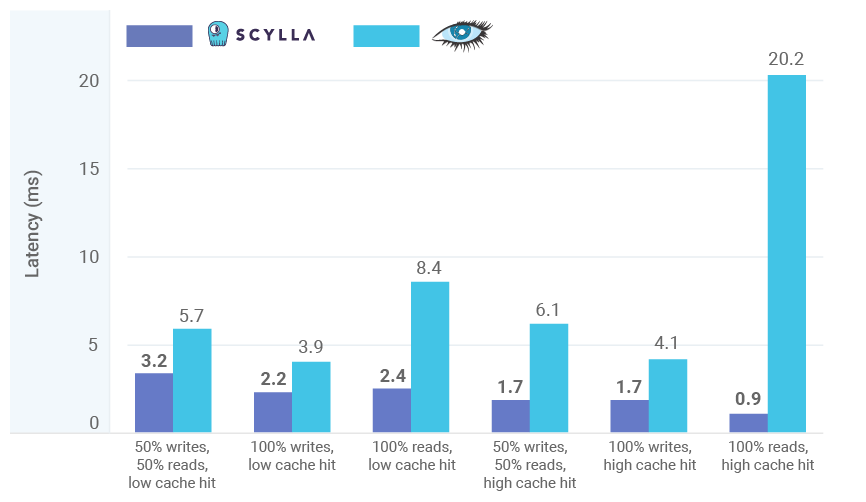
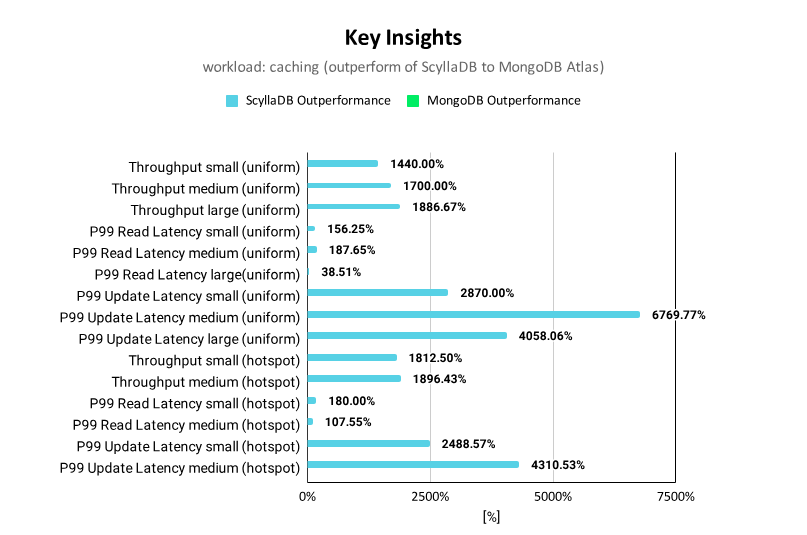
Selecting the best NoSQL database for your application is a business-critical task. That’s why we constantly compare ScyllaDB vs. other NoSQL databases for throughput and latency. Database latency determines your application speed, while database throughput defines how many users your application can service.
VS
Database Benchmark
ScyllaDB vs Apache Cassandra - Database Benchmark
ScyllaDB has 2x-5x better throughput and much better latencies than Cassandra 4.0
ScyllaDB adds and replaces nodes far faster than Cassandra 4.0
ScyllaDB finishes compaction 32x faster than Cassandra 4.0
A ScyllaDB cluster can be 10X smaller and 2.5X less expensive, yet still outperform Cassandra 4.0 by 42%
ScyllaDB tested the same workload on equivalent hardware and achieved 40% to 100% greater throughput than Aerospike
A scaled-down ScyllaDB cluster should handle the same petabyte-scale workload for about $800K per year—roughly one-third less than Aerospike’s expected $1.23M annual cost.
Alternately, users could provision a cluster at the exact same size and equivalent cost as the one proposed by Aerospike, yet get far greater throughputs with ScyllaDB.
ScyllaDB sustained writes at 7.5 million inserts per second with 4 ms P99 latencies. While Aerospike maintained ≤1ms P99 latencies, it provided significantly lower throughput than ScyllaDB.
Felipe Mendes
Solutions Architect
1:1 Technical Strategy Session
Technical Strategy Session
Schedule a technical consultation with a ScyllaDB Solutions Architect.