Introduction
A highly available time-series solution requires an efficient tailored front-end framework and a backend database with a fast ingestion rate. KairosDB provides a simple and reliable way to ingest and retrieve sensors’ information or metrics, while ScyllaDB provides a highly reliable and performant backend database that scales indefinitely, and can store large quantities of time-series data.
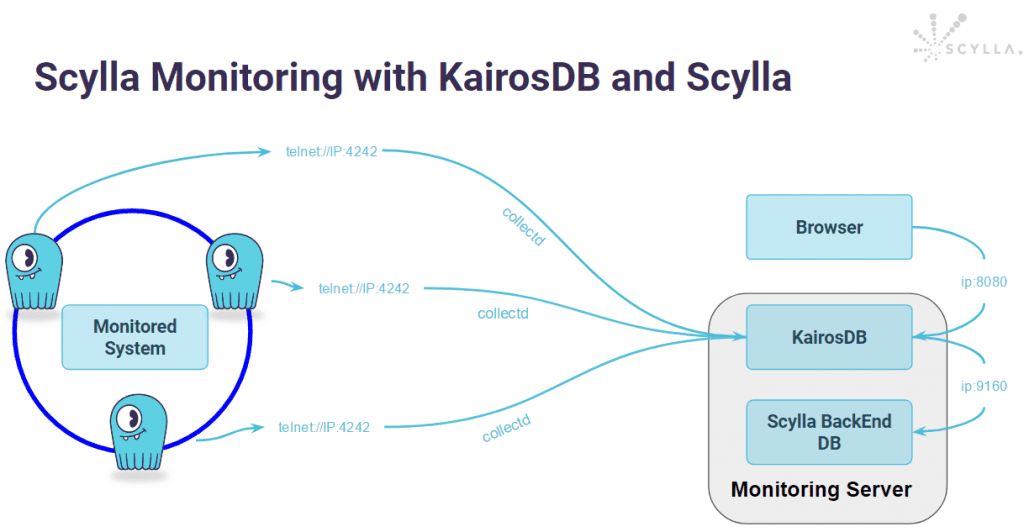
This post describes how metrics from any monitored system, in this example ScyllaDB metrics from one ScyllaDB cluster, are stored in a monitoring solution backend database based on KairosDB and ScyllaDB. Collectd will be used to push ScyllaDB metrics into KairosDB via telnet protocol, and KairosDB will store the data on a separate ScyllaDB cluster via Thrift API. Essentially, ScyllaDB will be storing the metrics of another ScyllaDB cluster. 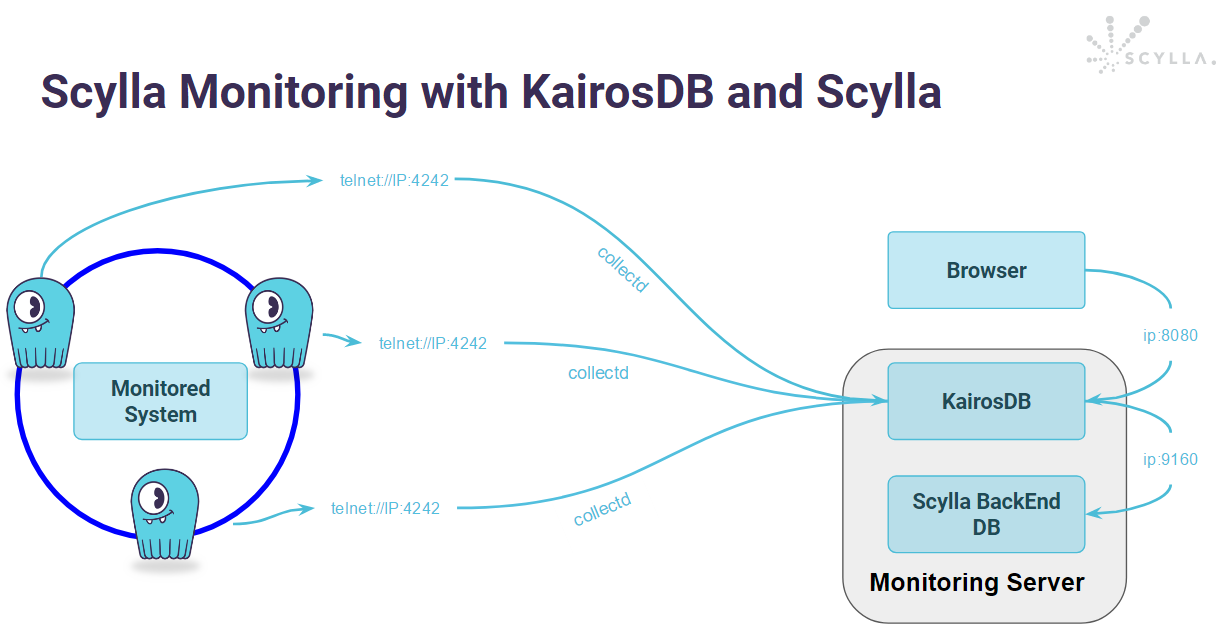
KairosDB
KairosDB is a fast distributed scalable time-series database. It was initially a rewrite of the original OpenTSDB project, but evolved to a different system for which data management, data processing, and visualization are fully separated. (More on KairosDB and ScyllaDB can be found here.)
Collectd
Collectd gathers metrics from various sources, e.g. the operating system, applications, log-files and external devices, and stores the information or makes it available over the network. The collected metrics are used to monitor systems, find performance bottlenecks and predict future system load (i.e. capacity planning.)
Why favor ScyllaDB and KairosDB over other choices?
KairosDB is a stateless shim layer on top of ScyllaDB that doesn’t touch the ingress. The combination of ScyllaDB and KairosDB allows infinite scale out of the ScyllaDB storage layer and puts an end to small siloed islands of monitoring and the problems of scaling a monitoring solution. ScyllaDB also provides best of-class high availability and top performance. Now without further ado, let’s jump to the setup.
Setup
You will need the following minimal setup for this procedure:
- ScyllaDB cluster to be monitored
- KairosDB node
- ScyllaDB cluster acting as backend database to store KairosDB data (It is recommended to install ScyllaDB in a cluster, to benefit from high availability)
The Procedure
1. Download KairosDB
- Go to: https://github.com/kairosdb/kairosdb/releases
- Download “kairosdb-1.1.3-1.tar.gz” file to your soon-to-be KairosDB node
2. KairosDB requires Java (and JAVA_HOME setting)
See procedure here: http://askubuntu.com/questions/175514/how-to-set-java-home-for-java
3. Extract the KairosDB file on the node
4. Configure KairosDB
- Go to: https://kairosdb.github.io/docs/GettingStarted.html
- Follow the instructions in “Using With Cassandra” section
In conf/kairosdb.properties file:
- Change the kairosdb.service.datastore property to the datastore you wish to use:
kairosdb.service.datastore=org.kairosdb.datastore.cassandra.CassandraModule
- In the Cassandra section:
kairosdb.datastore.cassandra.host_list=[scylla_host_ip1]:9160,[scylla_host_ip2]:9160, .. ,[scylla_host_ipN]:9160 kairosdb.datastore.cassandra.keyspace=kairosdb
5. Start KairosDB
Note: it is not required to start KairosDB with root (sudo) privileges. Change to the bin directory and start KairosDB using one of the following commands:
- To start KairosDB and run in the foreground type
> ./kairosdb.sh run
- To run KairosDB as a background process type
> ./kairosdb.sh start
- To stop KairosDB when running as a background process type
> ./kairosdb.sh stop
6. Verify KairosDB keyspace and tables are available in ScyllaDB
- Connect to one of the ScyllaDB cluster nodes you configured in step 4
- Open cqlsh -> run: ‘cqlsh [node_ip]’
- Check that the keyspace and tables were created
cqlsh> DESCRIBE TABLES -> you should find the keyspace value you used in step 4 with three tables. Keyspace kairosdb
—————–
data_points row_key_index string_index
7. Verify SELinux is disabled on the to-be monitored ScyllaDB cluster (on all nodes)
- Check SELinux status -> run: ‘sudo sestatus’
- If ‘enabled’, disable it by doing the following:
- Edit selinux config file: ‘sudo vi /etc/selinux/config’
- Modify ‘SELINUX=disabled’ -> save
- Reboot node
8. Push data from the to-be monitored ScyllaDB cluster to kairosdb using collectd
Perform the following on each of your scylla cluster nodes:
- sudo yum install git -y
- git clone https://github.com/kairosdb/collectd-kairosdb.git
- sudo cp collectd-kairosdb/kairosdb_writer.py /usr/lib64/collectd/.
- vi collectd-kairosdb/kairosdb.conf -> KairosDBURI “telnet://[KairosDB_IP]:4242”
- sudo bash
- cat collectd-kairosdb/kairosdb.conf >> /etc/collectd.d/scylla.conf
- sudo systemctl restart collectd
(Note: ScyllaDB comes with collectd running by default, so no need to install it, only configure it.)
9. Generate some traffic on the monitored ScyllaDB cluster, for example by using Cassandra-stress:
cassandra-stress write n=10000000 -mode cql3 native -node [scylla_ip1],[scylla_ip2]…
Execute Queries on KairosDB (web UI / REST-API)
Web UI
At this point you can open the KairosDB web UI by pointing your web browser to: http://[KairosDB_IP]:8080 to execute queries on the relevant metrics the and generate graphs. 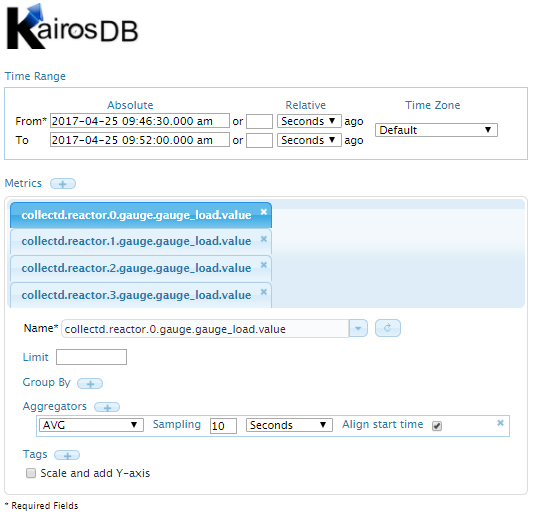
Here are several examples of metrics from the ScyllaDB nodes in the monitored system. This ScyllaDB cluster sends the ScyllaDB metrics to Kairos and later these metrics are stored on another ScyllaDB instance.

Query on AVG ‘reactor.0/1/2/3.gauge.gauge_load.value’ metric, to demonstrate the average CPU utilization of the ScyllaDB nodes in the monitored system.
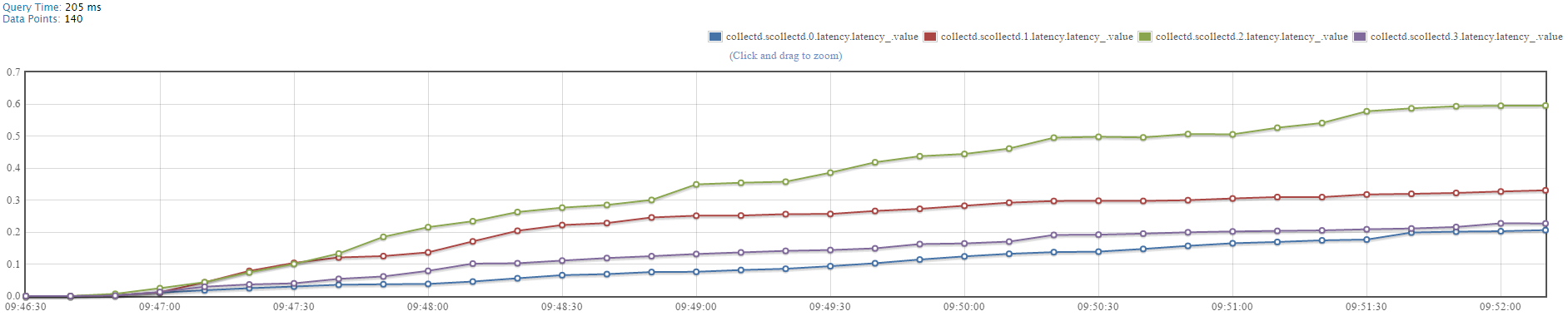
Query on MAX ‘scollectd.0/1/2/3.latency.latency_.value’ metric, to demonstrate the maximum latency of the ScyllaDB nodes in the monitored system.
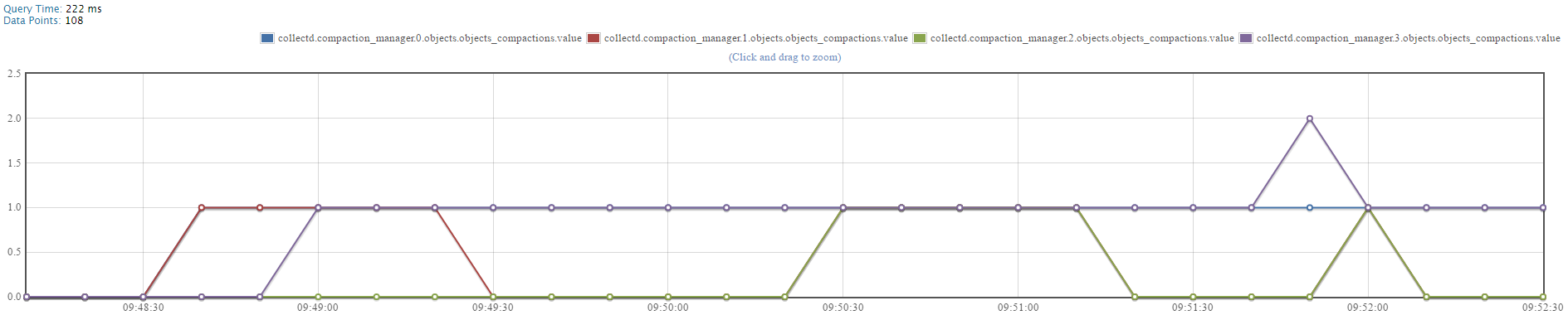
Query on MAX ‘compaction_manager.0/1/2/3.objects.objects_compactions.value’ metric, to demonstrate ongoing compactions on the ScyllaDB nodes in the monitored system.
REST-API
Another option is to use the KairosDB REST-API to query ScyllaDB metrics. This can be useful for triggering alerts.
Note: json format can be taken from the web UI, once you generate a query: http://[KairosDB_IP]:8080/api/v1/datapoints/query?query={json}
Ready to get started building a highly available time-series solution? Download ScyllaDB and get started today.



